Designing a Serverless RUM Ingestion Pipeline from Scratch
How I designed Snappi's event-driven ingestion architecture using S3 + SQS + Lambda -- built to scale to 800 RUMs/sec with multi-destination writes and zero operational overhead.
When I joined Snappi as a Software Engineer, the company was in its earliest stages. Snappi provides web acceleration services using proprietary CDN technologies and machine learning — and RUM (Real User Monitoring) is how we collect the performance data that feeds the acceleration engine. There was no ingestion pipeline, no infrastructure — just a product vision and a small team. I was responsible for designing and building the data pipeline from the ground up.
The Requirements
We needed an architecture that could grow with the business. Back-of-the-envelope calculations showed we’d need to support up to 100M events/month as the customer base scales, handle traffic spikes of ~390 RUMs/sec (10x average load), and write to multiple destinations simultaneously: ClickHouse for real-time analytics, Parquet for a data lake, and JSON for ML training datasets. As an early-stage startup with a small engineering team, operational overhead had to be minimal — we couldn’t afford to babysit infrastructure.
The Design
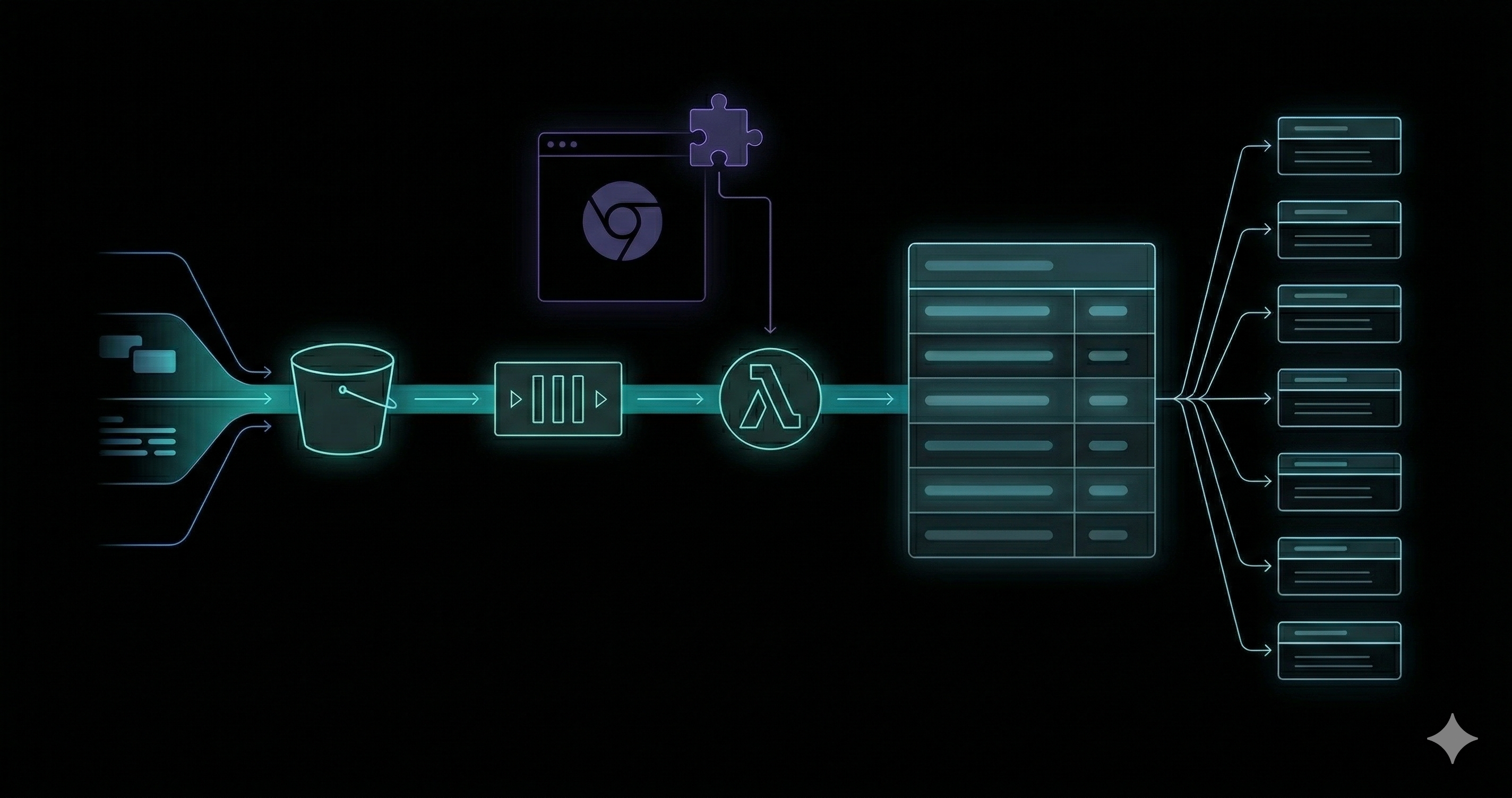
I proposed an event-driven pipeline built entirely on AWS managed services. The key insight was separating the event notification from the payload. RUM data lands in S3, which triggers an event notification to SQS. The SQS message only contains a pointer to the S3 object — not the data itself — which keeps us well under the 256KB SQS message size limit while supporting arbitrarily large payloads.
Lambda functions consume from SQS with dual-trigger batching: they fire either when a batch reaches a count threshold OR when a time window expires, whichever comes first. This ensures both high-throughput and low-latency processing.
Multi-Destination Writes
One of the most impactful design decisions was writing to three destinations in parallel within each Lambda invocation: ClickHouse for real-time analytics queries, Parquet files in S3 for the data lake, and JSON exports for the ML training pipeline. Each destination has independent error handling — if the Parquet write fails, ClickHouse and JSON writes still succeed. CloudWatch alarms with Slack integration notify us of per-destination failures.
Infrastructure as Code
The entire pipeline is defined in AWS CDK with TypeScript. This includes reserved concurrency tiers per environment (prod=20, preprod=10, dev=5), CloudWatch dashboards, and alarm configurations. Everything is reproducible and version-controlled.
Scale Headroom
With 20 reserved concurrent Lambda executions processing batches of 200 events each, the architecture has a throughput ceiling of ~800 RUMs/sec. Even at projected 10x traffic spikes (~390 RUMs/sec), the pipeline operates at under 50% capacity. The unit economics work out to ~$0.000008 per RUM — costs scale proportionally with growth rather than requiring upfront provisioning. This is exactly the kind of infrastructure an early-stage startup needs: built to stay ahead of demand, not chase it.
Results
The pipeline auto-scales with traffic and requires zero manual intervention. Adding new output destinations is just a matter of adding a new write function to the Lambda handler — the architecture was designed for extensibility from day one.
Lessons Learned
The biggest takeaway was the value of keeping payloads out of the queue. By using S3 as the data plane and SQS as the control plane, we got the best of both worlds: reliable event ordering and delivery from SQS, with unlimited payload sizes from S3. This pattern is applicable to any high-throughput ingestion system where message size is a concern.